One of my daily tasks is listening to customers. This involves checking blogs, forums, and newsgroups (they're still around!). I also check several Intranet sites, such as SharePoint sites for my projects. Doing this every day was taking a substantial amount of time. The problem wasn't digesting the information, or acting on it; it was getting to it. So I went looking for a one-stop solution. My requirements were:
Setting up Omea Reader
First, download Omea Reader from
here, then install it. This is a typical installation process, and the defaults work fine (though I chose not to install the Firefox plugin).
After installing, run Omea Reader. It asks about a Database Path and Log Files Path. The defaults here are also fine, so hit "OK". Next, it provides some import options. Just hit "Next >" until it requests User Information. Then, Enter your first and last name. Then, click "Add..." to add an email address. Finally, click "Finish".
At this point, Omea starts. We'll want to set some options, so go to Tools -> Options.  I changed these options:
I changed these options:
- General
- "Mark item read after displaying for 0 seconds"
- "Open links to Web pages In a new browser window"
- Mail Format
- Check "Include signature in outgoing messages", and paste in an appropriate signature (e.g., your company may require some legalese here).
- Plugins
- Uncheck everything except News and RSS; we won't be using Omea Reader's other functionality.
Clicked "OK", and Omea Reader restarts. Then, click on the "All Resources" tab and set options in the "View" menu. I set the following options:
- Uncheck "Shortcut Bar"
- Uncheck "Workspace Bar"
- Check "AutoPreview -> All Items"
Omea Reader now looks something like this: 
Finally, after setting options, delete the feeds that came with Omea Reader. First, click on the "Feeds" tab. Then, in the bottom-left section, you'll see three feeds. Select all of these, then delete them with the Delete key.
Adding Newsgroups
To add newsgroups to Omea Reader, click the "Tools -> Manage Newsgroups" menu item. This brings up the "Manage Newsgroups" dialog. Clicking on the "Add..." button on the bottom left lets you add news servers.
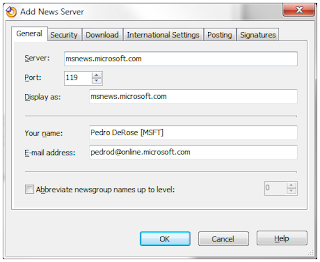
Set the server name. The other fields fill in automatically, but you can change them. If your server requires a login (such as Microsoft's privatenews.microsoft.com), click on the "Security" tab. Next, check "Authentication required", then set the user name and password. Finally, click "OK" to add the server.
Now you can subscribe to newsgroups. First, select a news server on the left. Then, check the newsgroups of interest on the right. By typing into the "Display newsgroups which contain:" field, you can filter the available newsgroups.  Finally, click "OK", and Omea Reader will download posts.
Finally, click "OK", and Omea Reader will download posts.
Filtering Posts
If you are interested in only some posts, Omea Reader can filter incoming posts. For example, you can create a rule that deletes all posts from a newsgroup except those containing particular words. First click on the menu item "Tools -> Manage Rules -> Action Rules". Then, in the dialog, click the "New..." button on the right. This brings up the "New Action Rule" dialog.
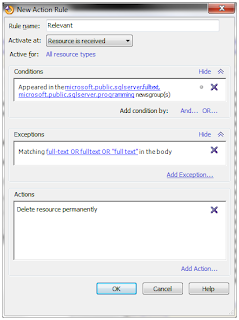
Give the rule a name, such as "Relevant". Then, under the "Conditions" field, click on "Add Condition...". Next, select "News Conditions -> Appeared in the specified newsgroup(s)", then click the "OK" button. This adds an entry in the "Conditions" field. Click on the blue "specified" link to select the newsgroups to filter.
Then, click on "Add Exception..." under the "Exceptions" field. Next, select "Text Query Conditions -> Matching query in the body", then click the "OK" button. This adds an entry in the "Exceptions" field. Click on the blue "query" link to enter keywords separated by "OR". Keywords can be single words, or phrases in double-quotes. For example, I use this query to keep only posts related to full-text searching: full-text OR fulltext OR "full text". To also search the post subject, repeat these steps, but select the exception "Matching query in the subject/header".
Finally, click on "Add Action..." under the "Actions" field. Check "Delete resource permanently", then click the "OK" button. This takes you back to the "Rules Manager" dialog. Click the "OK" button here to save your rule.
To apply your rule immediately, select the "Actions -> Apply Rules" menu item. Here, select "All resources", and check your rule. Finally, click the "OK" button. 
Adding Feeds
Feeds let you keep up with forums, blogs, search engine results, SharePoint lists, etc. I use three types of feeds:
- Direct feeds: Many blogs, forums, and SharePoint sites provide feeds. For example, MSDN lets you subscribe to a forum, or even to searches on forums. Look for the RSS icon
 , or a link similar to "Subscribe to Feed".
, or a link similar to "Subscribe to Feed".
- Search Engines: Some engines let you subscribe to searches as feeds. This is good for tracking a topic, or searching a site (such as forums without direct feeds). On Bing, transform searches into feeds by adding "&format=rss" to the URL. Google provides Google Alerts, which support various searches, including blog searches. In both engines, use "site:www.example.com" to search only a particular site. Unfortunately, these feeds return items as the search engine crawls them, so they can sometimes be very stale.
- Scraping pages: When there's no direct feed, and freshness is important, Dapper provides an easy way to scrape pages as RSS feeds. This is also good for scraping data not typically in feeds, such as the result count for a search.
Some representative examples of feeds I check are:
- MSDN feed for the SQL Server XML forum
- Bing searches over SQL Monster, such as ("column set" OR "column sets") site:www.sqlmonster.com/Uwe/Forum.aspx/.
- Google Blog searches (through Google Alerts), such as ("sparse columns" OR semi-structured) "sql server" -job.
- SharePoint lists on project sites, such as the Tasks or Announcements list.
However you obtain the feed, copy its URL with Ctrl-C. Then, in Omea Reader, click the menu item "Tools -> Subscribe to a Feed." The dialog that pops up will auto-paste the feed URL into the proper field, so just hit "Next >".  Omea Reader will then fetch the feed's name. Finally, click the "Finish" button to add the feed. Repeat these steps with as many feeds as you like.
Omea Reader will then fetch the feed's name. Finally, click the "Finish" button to add the feed. Repeat these steps with as many feeds as you like.
Daily Use
After adding newsgroups and feeds, click on the "All Resources" tab to see your posts. I recommend deleting all these initial posts and starting fresh. Then, each day, start Omea Reader. It will download the day's posts automatically.
You can answer newsgroup posts from Omea Reader. For feed posts, clicking on the "Source" link takes you to the original post, where you can reply through the site's interface. This daily routine takes only a few minutes a day, and is much more efficient than visiting each newsgroup, blog, and forum individually.











